

At one time or another, we have all been frustrated by trying to set a password, only to have it rejected as too weak. We are also told to change our choices regularly. Obviously such measures add safety, but how exactly?
I will explain the mathematical rationale for some standard advice, including clarifying why six characters are not enough for a good password and why you should never use only lowercase letters. I will also explain how hackers can uncover passwords even when stolen data sets lack them.
ChOose#W!sely@*
On supporting science journalism
If you're enjoying this article, consider supporting our award-winning journalism by subscribing. By purchasing a subscription you are helping to ensure the future of impactful stories about the discoveries and ideas shaping our world today.
Here is the logic behind setting hack-resistant passwords. When you are asked to create a password of a certain length and combination of elements, your choice will fit into the realm of all unique options that conform to that rule—into the “space” of possibilities. For example, if you were told to use six lowercase letters—such as, afzjxd, auntie, secret, wwwwww—the space would contain 266, or 308,915,776, possibilities. In other words, there are 26 possible choices for the first letter, 26 possible choices for the second, and so forth. These choices are independent: you do not have to use different letters, so the size of the password space is the product of the possibilities, or 26 x 26 x 26 x 26 x 26 x 26 = 266.
If you are told to select a 12-character password that can include uppercase and lowercase letters, the 10 digits and 10 symbols (say, !, @, #, $, %, ^, &, ?, / and +), you would have 72 possibilities for each of the 12 characters of the password. The size of the possibility space would then be 7212 (19,408,409,961,765,342,806,016, or close to 19 x 1021).
That is more than 62 trillion times the size of the first space. A computer running through all the possibilities for your 12-character password one by one would take 62 trillion times longer. If your computer spent a second visiting the six-character space, it would have to devote two million years to examining each of the passwords in the 12-character space. The multitude of possibilities makes it impractical for a hacker to carry out a plan of attack that might have been feasible for the six-character space.
Calculating the size of these spaces by computer usually involves counting the number of binary digits in the number of possibilities. That number, N, is derived from this formula: 1 + integer(log2(N)). In the formula, the value of log2(N) is a real number with many decimal places, such as log2(266) = 28.202638…. The “integer” in the formula indicates that the decimal portion of that log value is omitted, rounding down to a whole number—as in integer(28.202638… 28). For the example of six lowercase letters above, the computation results in 29 bits; for the more complex, 12-character example, it is 75 bits. (Mathematicians refer to the possibility spaces as having entropy of 29 and 75 bits, respectively.) The French National Cybersecurity Agency (ANSSI) recommends spaces having a minimum of 100 bits when it comes to passwords or secret keys for encryption systems that absolutely must be secure. Encryption involves representing data in a way that ensures it cannot be retrieved unless a recipient has a secret code-breaking key. In fact, the agency recommends a possibility space of 128 bits to guarantee security for several years. It considers 64 bits to be very small (very weak); 64 to 80 bits to be small; and 80 to 100 bits to be medium (moderately strong).
Moore’s law (which says that the computer-processing power available at a certain price doubles roughly every two years) explains why a relatively weak password will not suffice for long-term use: over time computers using brute force can find passwords faster. Although the pace of Moore’s law appears to be decreasing, it is wise to take it into account for passwords that you hope will remain secure for a long time.
For a truly strong password as defined by ANSSI, you would need, say, a sequence of 16 characters, each taken from a set of 200 characters. This would make a 123-bit space, which would render the password close to impossible to memorize. Therefore, system designers are generally less demanding and accept low- or medium-strength passwords. They insist on long ones only when the passwords are automatically generated by the system, and users do not have to remember them.
There are other ways to guard against password cracking. The simplest is well known and used by credit cards: after three unsuccessful attempts, access is blocked. Alternative ideas have also been suggested, such as doubling the waiting time after each successive failed attempt but allowing the system to reset after a long period, such as 24 hours. These methods, however, are ineffective when an attacker is able to access the system without being detected or if the system cannot be configured to interrupt and disable failed attempts.
.jpg?w=2000)
Credit: Jonathan Knowles Getty Images
How Long Does It Take to Search All Possible Passwords?
For a password to be difficult to crack, it should be chosen randomly from a large set, or “space,” of possibilities. The size, T, of the possibility space is based on the length, A, of the list of valid characters in the password and the number of characters, N, in the password. The size of this space (T = AN) may vary considerably.
Each of the following examples specifies values of A, N, T and the number of hours, D, that hackers would have to spend to try every permutation of characters one by one. X is the number of years that will have to pass before the space can be checked in less than one hour, assuming that Moore’s law (the doubling of computing capacity every two years) remains valid. I also assume that in 2019, a computer can explore a billion possibilities per second. I represent this set of assumptions with the following three relationships and consider five possibilities based on values of A and N:
Relationships
T = AN
D = T/(109 × 3,600)
X = 2 log2[T/(109 × 3,600)]
Results
_________________________________
If A = 26 and N = 6, then T = 308,915,776
D = 0.0000858 computing hour
X = 0; it is already possible to crack all passwords in the space in under an hour
_________________________________
If A = 26 and N = 12, then T = 9.5 × 1016
D = 26,508 computing hours
X = 29 years before passwords can be cracked in under an hour
_________________________________
If A = 100 and N = 10, then T = 1020
D = 27,777,777 computing hours
X = 49 years before passwords can be cracked in under an hour
_________________________________
If A = 100 and N = 15, then T = 1030
D = 2.7 × 1017 computing hours
X = 115 years before passwords can be cracked in under an hour
________________________________
If A = 200 and N = 20, then T = 1.05 × 1046
D = 2.7 × 1033 computing hours
X = 222 years before passwords can be cracked in under an hour
Weaponizing Dictionaries and Other Hacker Tricks
Quite often an attacker succeeds in obtaining encrypted passwords or password “fingerprints” (which I will discuss more fully later) from a system. If the hack has not been detected, the interloper may have days or even weeks to attempt to derive the actual passwords.
To understand the subtle processes exploited in such cases, take another look at the possibility space. When I spoke earlier of bit size and password space (or entropy), I implicitly assumed that the user consistently chooses passwords at random. But typically the choice is not random: people tend to select a password they can remember (locomotive) rather than an arbitrary string of characters (xdichqewax).
This practice poses a serious problem for security because it makes passwords vulnerable to so-called dictionary attacks. Lists of commonly used passwords have been collected and classified according to how frequently they are used. Attackers attempt to crack passwords by going through these lists systematically. This method works remarkably well because, in the absence of specific constraints, people naturally choose simple words, surnames, first names and short sentences, which considerably limits the possibilities. In other words, the nonrandom selection of passwords essentially reduces possibility space, which decreases the average number of attempts needed to uncover a password.
Below are the first 25 entries in one of these password dictionaries, listed in order, starting with the most common one. (I took the examples from a database of five million passwords that was leaked in 2017 and analyzed by SplashData.)
1. 123456
2. password
3. 12345678
4. qwerty
5. 12345
6. 123456789
7. letmein
8. 1234567
9. football
10. iloveyou
11. admin
12. welcome
13. monkey
14. login
15. abc123
16. starwars
17. 123123
18. dragon
19. passw0rd
20. master
21. hello
22. freedom
23. whatever
24. qazwsx
25. trustno1
If you use password or iloveyou, you are not as clever as you thought! Of course, lists differ according to the country where they are collected and the Web sites involved; they also vary over time.
For four-digit passwords (for example, the PIN code of SIM cards on smartphones), the results are even less imaginative. In 2013, based on a collection of 3.4 million passwords each containing four digits, the DataGenetics Web site reported that the most commonly used four-digit sequence (representing 11 percent of choices) was 1234, followed by 1111 (6 percent) and 0000 (2 percent). The least-used four-digit password was 8068. Careful, though, this ranking may no longer be true now that the result has been published. The 8068 choice appeared only 25 times among the 3.4-million four-digit sequences in the database, which is much less than the 340 uses that would have occurred if each four-digit combination had been used with the same frequency. The first 20 series of four digits are: 1234; 1111; 0000; 1212; 7777; 1004; 2000; 4444; 2222; 6969; 9999; 3333; 5555; 6666; 1122; 1313; 8888; 4321; 2001; 1010.
Even without a password dictionary, using differences in frequency of letter use (or double letters) in a language makes it possible to plan an effective attack. Some attack methods also take into account that, to facilitate memorization, people may choose passwords that have a certain structure—such as A1=B2=C3, AwX2AwX2 or O0o.lli. (which I used for a long time)—or that are derived by combining several simple strings, such as password123 or johnABC0000. Exploiting such regularities makes it possible to for hackers to speed up detection.
Making Hash of Hackers
As the main text explains, instead of storing clients’ passwords, Internet servers store the “fingerprints” of these passwords: sequences of characters that are derived from the passwords. In the event of an attack, the use of fingerprints can make it is very difficult, if not impossible, for hackers to use what they find.
The transformation is achieved by using algorithms known as cryptographic hash functions. These are meticulously developed processes that transform a data file, F, however long it may be, into a sequence, h(F), called a fingerprint of F. For example, the hash function SHA256 transforms the phrase “Nice weather” into:
DB0436DB78280F3B45C2E09654522197D59EC98E7E64AEB967A2A19EF7C394A3
(64 hexadecimal, or base 16, characters, which is equivalent to 256 bits)
Changing a single character in the file completely alters its fingerprint. For example, if the first character of Nice weather is changed to lowercase (nice weather), the hash SHA256 will generate another fingerprint:
02C532E7418CD1B57961A1B090DB6EC37B3C58380AC0E6877F3B6155C974647E
You can do these calculations yourself and check them at https://passwordsgenerator.net/sha256-hash-generator or www.xorbin.com/tools/sha256-hash-calculator
Good hash functions produce fingerprints that are similar to those that would be obtained if the fingerprint sequence was uniformly chosen at random. In particular, for any possible random result (a sequence of 64 hexadecimal characters), it is impossible to find a data file F with this fingerprint in a reasonable amount of time.
There have been several generations of hash functions. The SHA0 and SHA1 generations are obsolete and are not recommended. The SHA2 generation, including SHA256, is considered secure.
The Take-Home for Consumers
Taking all this into account, properly designed Web sites analyze the passwords proposed at the time of their creation and reject those that would be too easy to recover. It is irritating, but it’s for your own good.
The obvious conclusion for users is that they must choose their passwords randomly. Some software does provide a random password. Be aware, however, that such password-generating software may, deliberately or not, use a poor pseudo-random generator, in which case what it provides may be imperfect.
You can check whether any of your passwords has already been hacked by using a Web tool called Pwned Passwords (https://haveibeenpwned.com/Passwords). Its database includes more than 500 million passwords obtained after various attacks.
I tried e=mc2e=mc2, which I liked and believed to be secure, and received an unsettling response: “This password has been seen 114 times before.” Additional attempts show that it is difficult to come up with easy-to-memorize passwords that the database does not know. For example, aaaaaa appeared 395,299 times; a1b2c3d4, 113,550 times; abcdcba, 378 times; abczyx, 186 times; acegi, 117 times; clinton, 18,869 times; bush, 3,291 times; obama, 2,391 times; trump, 859 times.
It is still possible to be original. The Web site did not recognize the following six passwords, for example: eyahaled (my name spelled backward); bizzzzard; meaudepace and modeuxpass (two puns on the French for “password”); abcdef2019; passwaurde. Now that I’ve tried them, I wonder if the database will add them when it next updates. In that case, I won’t use them.
Advice for Web Sites
Web sites, too, follow various rules of thumb. The National Institute of Standards and Technology recently published a notice recommending the use of dictionaries to filter users’ password choices.
Among the rules that a good Web server designer absolutely must adhere to is, do not store plaintext lists of usernames and passwords on the computer used to operate the Web site.
The reason is obvious: hackers could access the computer containing this list, either because the site is poorly protected or because the system or processor contains a serious flaw unknown to anyone except the attackers (a so-called zero-day flaw), who can exploit it.
One alternative is to encrypt the passwords on the server: use a secret code that transforms them via an encryption key into what will appear to be random character sequences to anyone who does not possess the decryption key. This method works, but it has two disadvantages. First, it requires decrypting the stored password every time to compare it with the user’s entry, which is inconvenient. Second, and more seriously, the decryption necessary for this comparison requires storing the decryption key in the Web site computer’s memory. This key may therefore be detected by an attacker, which brings us back to the original problem.
A better way to store passwords is through what are called hash functions that produce “fingerprints.” For any data in a file—symbolized as F—a hash function generates a fingerprint. (The process is also called condensing or hashing.) The fingerprint—h(F)—is a fairly short word associated with F but produced in such a way that, in practice, it is impossible to deduce F from h(F). Hash functions are said to be one-way: getting from F to h(F) is easy; getting from h(F) to F is practically impossible. In addition, the hash functions used have the characteristic that even if it is possible for two data inputs, F and F', to have the same fingerprint (known as a collision), in practice for a given F, it is almost impossible to find an F' with a fingerprint identical to F.
Using such hash functions allows passwords to be securely stored on a computer. Instead of storing the list of paired usernames and passwords, the server stores only the list of username/fingerprint pairs.
When a user wishes to connect, the server will read the individual’s password, compute the fingerprint and determine whether it corresponds to the list of stored username/fingerprint pairs associated with that username. That maneuver frustrates hackers because even if they have managed to access the list, they will be unable to derive the users’ passwords, inasmuch as it is practically impossible to go from fingerprint to password. Nor can they generate another password with an identical fingerprint to fool the server because it is practically impossible to create collisions.
Still, no approach is foolproof, as is highlighted by frequent reports of the hacking of major sites. In 2016, for example, data from a billion accounts were stolen from Yahoo!
For added safety, a method known as salting is sometimes used to further impede hackers from exploiting stolen lists of username/fingerprint pairs. Salting is the addition of a unique random string of characters to each password. It ensures that even if two users employ the same password, the stored fingerprints will differ. The list on the server will contain three components for each user: username, fingerprint derived after salt was added to the password, and the salt itself. When the server checks the password entered by a user, it adds the salt, computes the fingerprint and compares the result with its database.
Even when user passwords are weak, this method considerably complicates the hacker’s work. Without salting, a hacker can compute all the fingerprints in a dictionary and see those in the stolen data; all the passwords in the hacker’s dictionary can be identified. With salting, for every salt used, the hacker must compute the salted fingerprints of all the passwords in the hacker’s dictionary. For a set of 1,000 users, this multiplies by 1,000 the computations required to use the hacker’s dictionary.
Survival of the Fittest
It goes without saying that hackers have their own ways of fighting back. They face a dilemma, though: their simplest options either take a lot of computing power or a lot of memory. Often neither option is viable. There is, however, a compromise approach known as the rainbow table method (see “Rainbow Tables Help Hackers”).
In the age of the Internet, supercomputers and computer networks, the science of password setting and cracking continues to evolve—as does the relentless struggle between those who strive to protect passwords and those who are determined to steal, and potentially abuse, them.
Rainbow Tables Help Hackers
Say you are a hacker looking to exploit data that you have acquired. These data consist of username/fingerprint pairs, and you know the hash function (see “Making Hash of Hackers”). The password is contained in the possibility space of strings of 12 lowercase letters, which corresponds to 56 bits of information and 2612 (9.54 x 1016) possible passwords.
At least two strong approaches are open to you:
Method 1. You scroll through the entire space of passwords. You calculate the fingerprint, h(P), for each password, checking to see whether it appears in the stolen data. You do not need a lot of memory, because prior results are deleted with each new attempt, although you do, of course, have to keep track of the possibilities that have been tested.
Scrolling through all the possible passwords in this way takes a long time. If your computer runs a billion tests per second, you will need 2612/(109 x 3,600 x 24) days (1,104 days), or about three years to complete the task. The feat is not impossible; if you happen to have a computer network of 1,000 machines, one day will suffice. It is not feasible, however, to repeat such a calculation every time you wish to test additional data, such as if you obtain a new set of username/fingerprint pairs. (Because you have not saved the results of your computations, you would need an additional 1,104 days to process the new information.)
Method 2. You say to yourself, “I’ll compute the fingerprints of all possible passwords, which will take time, and I’ll store the resulting fingerprints in a big table. Then I’ll have to find only a password fingerprint in the table to identify the corresponding password in the stolen data.”
You will need (9.54 x 1016) x (12 + 32) bytes of memory because the task requires 12 bytes for the password and 32 bytes for the fingerprint if the fingerprint contains 256 bits (assuming an SHA256 function). That’s 4.2 x 1018 bytes, or 4.2 million hard disks with a capacity of one terabyte.
This memory requirement is too large. Method 2 is no more feasible than method 1. Method 1 requires too many computations, and method 2 requires too much memory. Both cases are problematic: either each new password takes too long to compute, or precomputing all possibilities and storing all the results is too large a task.
Is there some compromise that requires less computing power than method 1 and less memory than required for method 2? Indeed, there is. In 1980 Martin Hellman of Stanford University suggested an approach that was improved in 2003 by Philippe Oechslin of the Swiss Federal Institute of Technology in Lausanne and further refined more recently by Gildas Avoine of the National Institute of Applied Sciences of Rennes (INSA Rennes) in France. It demands less computing power than method 1 in exchange for using a little more memory.
The Beauty of the Rainbow
Here is how it works: First, we need a function R that transforms a fingerprint h(P) into a new password R(h(P)). One might, for instance, consider fingerprints as numbers written in the binary numeral system and consider passwords as numbers written in the K numeral system, where K is the number of allowable symbols for passwords. Then the function R converts data from the binary numeral system to the K numeral system. For every fingerprint h(P), it computes a new password R(h(P)).
Now, with this function R, we can precompute data tables called rainbow tables (so named perhaps because of the multicolored way these tables are depicted).
To generate a data point in this table, we start from a possible password P0, compute its fingerprint, h(P0) and then compute a new possible password R(h(P0)), which becomes P1. Next, we continue this process from P1. Without storing anything other than P0, we compute the sequence P1, P2,... until the fingerprint starts with 20 zeros; that fingerprint is designated h(Pn). Such a fingerprint occurs only once in about 1,000,000 fingerprints because the result of a hash function is similar to result of a uniform random draw, and 220 is roughly equal to 1,000,000. The password/fingerprint pair [P0, h(Pn)], containing the fingerprint that starts with 20 zeros is then stored in the table.
A very large number of pairs of this type are computed. Each password/fingerprint pair [P0, h(Pn)] represents the sequence of passwords P0, P1,… Pn and their fingerprints, but the table does not store those intermediate calculations. The table thus lists many password/fingerprint pairs and represents many more (the intermediates, such as P1 and P2, that can be derived from the listed pairs). But, of course, there may be gaps: some passwords may be absent from all the chains of calculations.
For a good database with almost no gaps, the memory needed to store the calculated pairs is a million times smaller than that needed for method 2, as described earlier. That is less than four one-terabyte hard disks. Easy. Also, as will be seen, using the table to derive passwords from stolen fingerprints is quite doable.
Let us see how the data stored on the hard disks makes it possible to determine a password in a given space in just a few seconds. Assume that there are no gaps; precomputation of the table takes into account all the passwords of a designated type—for example, 12-character passwords taken from the 26 letters of the alphabet.
A fingerprint f0 in a stolen data set can be used to reveal the associated password in the following way. Calculate h(R(f0)) to arrive at a new fingerprint, f1, then calculate h(R(f1)) to get f2, and so on, until you get to a fingerprint that begins with 20 zeros: fm. Then check the table to see which original password, P0, the fingerprint fm is associated with. Based on P0, calculate the passwords and fingerprints h1, h2,... that follow until you inevitably generate the original fingerprint f0, designated hk. The password you are looking for is the one that gave rise to hk—in other words, R(hk – 1), which is one step earlier in the chain of calculations.
The computation time required is what it takes to look for fm in the table plus the time needed to compute the sequence of fingerprints from the associated password (h1, h2,…, hk)—which is about a million times shorter than the time needed to compute the table itself. In other words, the time needed is quite reasonable.
Thus, doing a (very long) precomputation and storing only part of the results makes it possible to retrieve any password with a known fingerprint in a reasonable amount of time.
The sequences below represent separate chains of calculations leading from passwords (Mo, No,..., Qo) to fingerprints and other passwords, until the desired fingerprint (and thus the password that precedes it) pops out. (The long dotted line represents may other lines similar to the top two.)
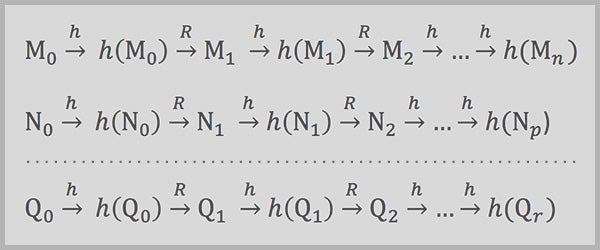
To summarize, by knowing the beginning and end of each chain of computations (the only things that are stored during precomputation), a hacker can retrieve any password from a fingerprint. In somewhat simplistic terms, starting from a stolen fingerprint—call it fingerprint X—a hacker would apply the R and h functions repeatedly, calculating a series of passwords and fingerprints until reaching a fingerprint with 20 zeros in front of it. The hacker would then look up that final fingerprint in the table (Fingerprint C in the example below) and identify its corresponding password (Password C).
Sample Table ExcerptPassword A—Fingerprint A
Password B—Fingerprint B
Password C—Fingerprint C
Password D—fingerprint D
Next, the hacker would apply the h and R functions again, beginning with the identified password, continuing on until one of the resulting fingerprints in the chain matches the stolen fingerprint:
Sample CalculationPassword C → fingerprint 1 → password 2-- → fingerprint 2 → password 3…. → password 22-- →fingerprint 23 [a match to fingerprint X!]
The match (fingerprint 23) would indicate that the previous password (password 22), from which the fingerprint was derived, is the one linked to the stolen fingerprint.
Many computations must be done to establish the first and last column of the rainbow table. By storing only the data in these two columns and by recomputing the chain, hackers can identify any password from its fingerprint.
