


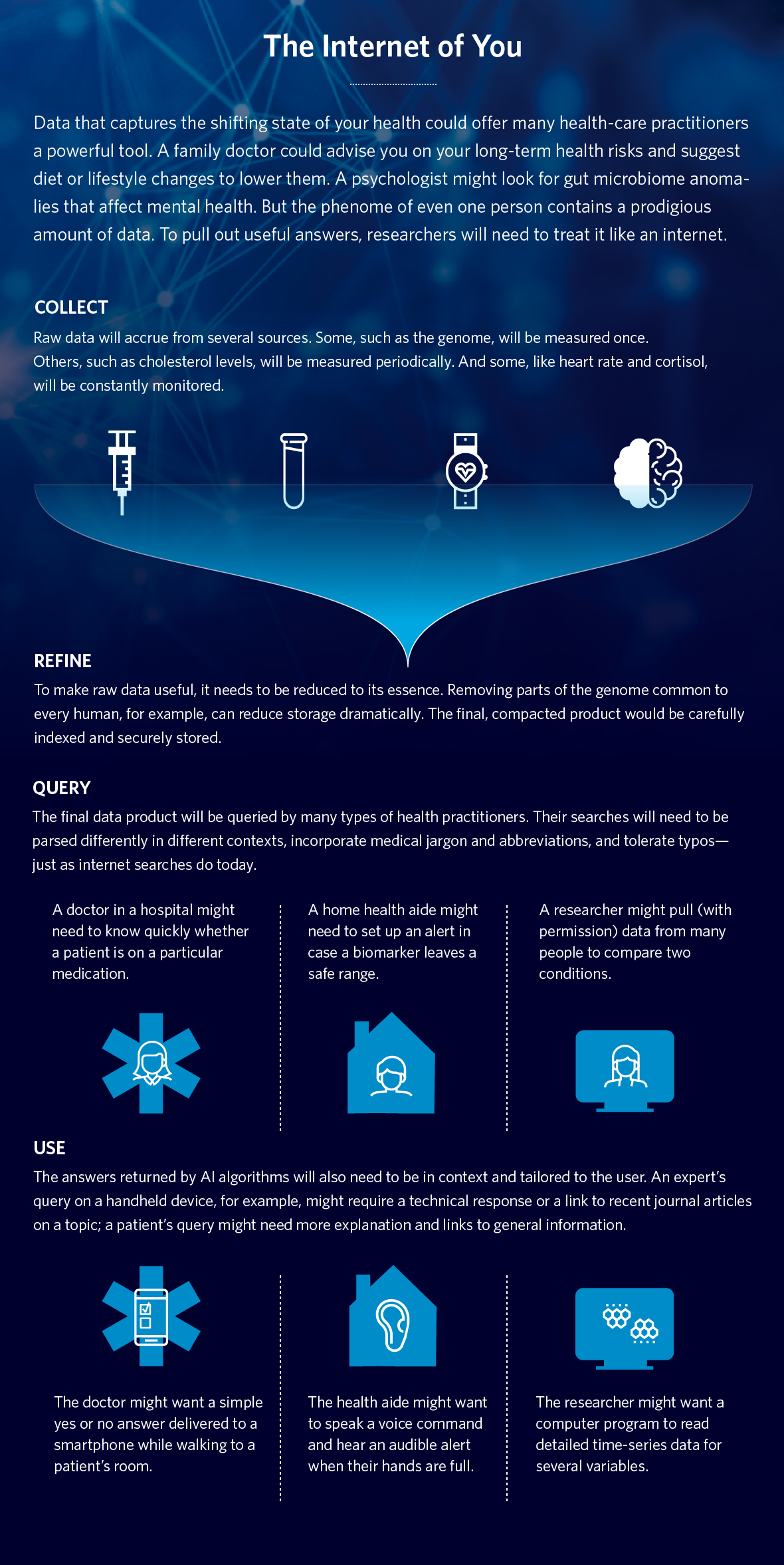
Doctors test our blood. Smartwatches count our steps. Nutrition apps track our diets. We’ve grown accustomed to having the status of our health measured routinely, and sometimes in real time.
In the not-too-distant future, however, inexpensive tests will reveal what’s going on inside our bodies by reading the dense, nanoscale information within our cells. Our doctors and our devices will be able to gather data on the activities of genes, proteins, metabolites, bacteria in our digestive tracts, plus real-time measurements of heart activity, exercise and stress hormones.
The idea is to supplement this raw data with electronic health records, consumer devices, classic blood tests, published research and more. Taken together, this data can help scientists identify which patients are more likely to respond positively to which medication, detect earlier when people are beginning to develop chronic illness, and then learn which next step is best, taking into account a patient’s particular genetic makeup.
Collecting so much data—much of it at a molecular scale—will produce vast amounts of information. In the phenome age, each of us will generate our own internet-size cloud of biological data. This personal source code, so to speak, will help us understand where we came from and how our bodies work, and it will help billions of people improve their lives. But we must find a way to make sense of it.
The task of finding meaning in this explosion of data presents a computational challenge of unprecedented scale. In a health-care world that stresses wellness, how do we tease actionable recommendations for each individual?
To start answering that question, my colleagues and I at Google Cloud have been applying the technologies of web-scale information retrieval—colloquially known as “search”—to the task of handling enormous volumes of data in the phenome age. In collaboration with Phenome Health, we are looking for aspects of phenomics that can be framed as information-retrieval problems.
We’ve come up with some interesting and promising ideas that we think may help doctors crack our individual source codes. This would create a vast storage of phenomes—the expression of our genomes—and give doctors great insight into wellness.
Dense and Voluminous
To get a feeling for how much data we’re talking about, let’s consider a sugar cube. A typical cube measures about one centimeter on each side. By comparison, a single nucleotide of DNA—one of the basic letters that make up our genes—would fit in a cube about a nanometer wide. That means that a volume of DNA the size of a sugar cube holds about a zettabit of data—that’s a 1 followed by 21 zeros. For context, that’s nearly the amount of data sent around the internet in 2012. And it would take hundreds of sugar cubes to equal the volume of a human body.
The first task is to capture this information. Advances in nanophotonics (the study of light at the nanometer scale) and neural networks (a method of machine intelligence inspired by the networks of cells in the human brain) have given us a new way to read dense chemical and biological information for a few dollars of raw materials and capture that information digitally. Today, most of that comes from expensive reagents—liquids that chemically process biological material. Instead, scientists can now use a small computer chip to count and read molecules in a blend of liquefied material by sensing their electromagnetic signatures.
Jen Dionne, a pioneer in the field of nanophotonics at Stanford University who developed this technology, is now focused on detecting and counting large assemblies of code, such as genomic biomarkers in human DNA, COVID-19 antibodies, and discarded cancer proteins in the blood. Ultima Genomics raised $600 million in funding in May 2022 to develop technology that can read a person’s DNA code for $100, a price low enough to create a new market for digital lab tests. Dionne’s nanophotonics is just one powerful technology that we hope will enable doctors to cost-effectively read source code from biological material in minutes.
Cleaning and Indexing
The next step is to come up with ways of accessing and organizing this data. Many companies now focus on “data normalization”—ways of retrieving, cleaning and organizing large pipelines of data for analysis. Once data is put in that form, it’s a relatively straightforward matter for an information-retrieval (IR) system to “crawl” it, much as a private search engine would crawl through a company’s web pages to catalog them.
Once an IR system has gathered this raw, unstructured data and given it some organization, we need to figure out what information we can extract from it and arrange it in a secure enclave for fast retrieval.
This next step, indexing, involves reducing the information to its smallest, quintessential components to make it easier to store and search. Computer engineers have a lot of experience in reducing large genomic sequencing files to variants of the 25,000 known genes so that it requires far less storage. We can reduce blood tests, tissue analysis and sensor data to a handful of numeric features, such as temperature, the count and concentration of molecules, lengths, weights and colors. Artificial-intelligence systems can also generate labels to describe what they see inside documents, images, videos, sounds and sensor readings. These labels take much less room than the original media, but are perfect for finding patterns.
Meaning from Data
After ensuring that our information is secure, indexed and compact, the next part of the data challenge is how to structure the query. In other words, what is the question we seek to answer?
Current search and database technologies map queries to representations of intent and meaning. Intent is often a collection of words, abbreviated symbols or tensors (a mathematical tool that can concisely represent information embedded within raw data) that together represent a concept. For phenomics, a query might also include a set of molecular concentrations, such as metabolites and proteins, and genomic markers, and ask for relevant research to help describe what might be happening.
The meaning of a query is what puts it in context. Computer engineers have gotten pretty good at building search engines that can extend a query to take context into account, saving people time and effort. For instance, when we search for “pizza” on our phones while traveling, we may really mean “pizza near me, available now.” This way, a user can ask a simpler, shorter question, then have the computer fill out relevant context. For example, a caregiver might open a medical record for a particular individual within an EHR system, or view the pathology of a slide from another. The query "abx?" could mean, “Is the patient I’m viewing on antibiotics (abx)?"
The next step is determining what information elements are relevant. The earliest search, database and information-retrieval engines matched keywords in a query against keywords extracted from an information source. If an information source didn’t contain exact words and spellings from the query, it was considered irrelevant.
Recent developments in natural-language understanding, automated speech recognition, knowledge graphs and user interfaces allow for more sophisticated and accommodating forms of matching. We can now find keywords that have similar phonetic spellings and correct for spelling mistakes. We can find keywords with similar meanings to our query, so that “large” and “big” are considered a match. We can find keywords that sound similar to what we say, so that “zeralto” matches the drug “Xarelto,” and “brahka one” matches the gene BRCA1. Knowledge graphs can help us match “abx” to “antibiotics,” and “nsclc” to “lung cancer.”
Special-purpose processors, some working in parallel to one another, can process these queries quickly. This is the way that many image and video search systems work today, for example, finding objects within Google Photos. Such processors would be well suited to handling the files from Dionne’s nanophotonics chip, Ultima’s whole genome sequence, x-rays, MRI images and other EHR media from hospitals and devices, which, even after being compressed, will be large.
The Presentation
Once we have made a rough cut at amassing all information that is relevant to a query, we need to further refine this list to highlight those elements that are the most useful. Ideally, we’d want to show an ordered list of results, where the top element is the best answer. A random ordering, by contrast, would require more time for doctors to look for an answer.
Search systems use a variety of mathematical techniques to prefer one piece of information over another. Most famously, Google’s PageRank algorithm settles the matter with a tautology: the most relevant web page was the one that had the most links from the other relevant web pages.
Today, search systems use hundreds, if not thousands, of analytical features to represent relevance. The page rank of a research report gives us the option to prefer well-cited research over less well-known research. In the context of phenomics, a recent biological measurement can get preference over older ones, or measurements from professional medical equipment may be preferred over consumer devices.
Once an information-retrieval system produces an initial generic ranking of relevant results, the ranking needs some fine-tuning. Artificial-intelligence systems can adjust the order of results based on who is doing the searching, the device they’re using, or where they’re making the search and when. For instance, cancer researchers may prefer to see new, peer-reviewed results from PubMed rather than older, more established and cited papers.
The final step is how to best present the set of relevant, ranked results. Presenting results has a lot to do with how users like to receive information, taking into account the devices they’re using, where they are, and so forth. Doctors speaking into a phone on the way to see a patient may prefer a succinct spoken answer, in their native language, followed by a concise display of results on their tablet. Caregivers who don’t have a free hand may want diagrams and charts projected in a live augmented-reality video feed. A researcher at a desk may prefer a screen full of detailed information, with data organized neatly in a spreadsheet for analysis.
A growing number of teams are using these types of techniques from information retrieval to modernize medicine and the study of the phenome. Sauvik Chatterjee and his colleagues describe a system that uses tensors and neural networks to detect cancers from methylated DNA found in blood samples. Qi Wu and collaborators combine sophisticated natural-language processing and vision techniques to build question-and-answer systems that explore the human genome. Sebastian Castillo-Hair and colleagues combine synthetic biology and machine learning to predict the efficacy of mRNA designs, improving the performance of COVID-19 vaccines.
Technology vendors will create secure, private enclaves for all this information, either on-premise or in cloud environments. These enclaves will follow strict guidelines for protecting private health data that are spelled out in laws, such as the U.S.’s Health Insurance Portability and Accountability Act (HIPAA) of 1996, the U.K.’s Data Privacy Act of 2018, and the E.U.’s General Data Protection Regulation. These laws establish strict rules for managing sensitive user data, ensuring security and privacy. Vendors will have to follow these rules and be certified by regulators. The cloud environments are operated by health-care organizations, such as hospitals, doctor’s offices and our medical insurers. (Google has written up best practices for protecting health data on Google Cloud.) These secure, private enclaves can deploy sophisticated technology to analyze our source code, better managing and preserving our health.
Soon, inexpensive tests will read the dense, nanoscale information within our cells, revealing what’s going on in our bodies. The data we now enjoy on the internet may soon be dwarfed by our own personal source code, helping us understand where we came from, how we work, and how to improve the lives of billions. We will literally be able to search for the meaning of life.
Scott Penberthy is director of applied AI at Google. Before that, he was technical director in the CTO’s office at Google, where he focused on cloud computing. He has also been a managing director of PwC and chief technology officer of several start-ups.
Find out more about Phenome Health’s efforts to transform the future of health care here. Learn more about phenomics, the new science of wellness, in other stories in this special report.
